Extracting Topic and Entity data useful in the Technology and Healthcare domains from unstructured text.
GLG is a management consultancy and self-styled World’s Insight Network. One of GLG’s main business roles is to connect clients with experts from its network of over 900,000 subject matter experts. It identifies Technology and Healthcare as particular areas of focus for its business delivery.
The problem at hand is that GLG lacks a suitable automated, AI-driven, scalable system to route requests to the appropriate experts. To do this, the verbiage of these requests can be leveraged to extract signifying information that will highlight the domain area and ultimately yield an expert recommendation.
The task, therefore, is to create a self-service application, into which the user will input a specific request, which may take the form:
“What is the 3-5 year outlook for e-commerce in Latin America?” Or: “What regulatory threats exist to the development of the genetic testing industry?” The requirement is that the finished tool will assign the incoming request to a the right expert or experts by means of machine learning techniques. Topic modeling and Named Entity Recognition are logical ways to ensure that requests are correctly routed and that noteworthy names, acronyms and organizations are highlighted.
Build LDA model. Run on provided dataset of 2.5 million articles from All The News dataset.
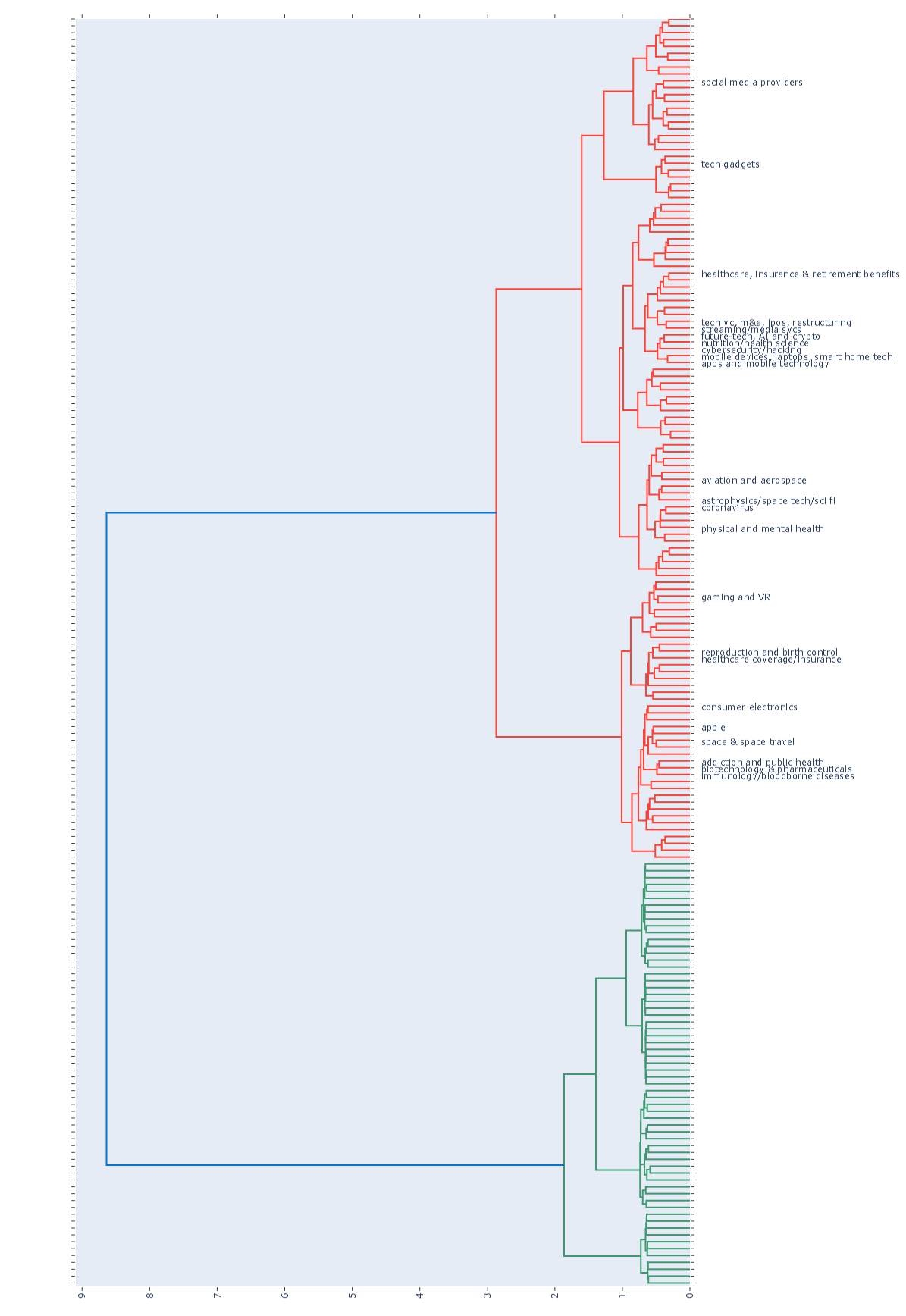
Below is the dictionary output created from the hand-labeled LDA output (265 LDA topics specified).

Use saved LDA model to predict topics for incoming queries:
Request: 'To what extent can the government / Central Bank influence the macro-economy?' primary topic: global macroeconomics Provide dendrogram plot of topics, with focus on topics relevant to the problem statement, specifically Healthcare and Technology:
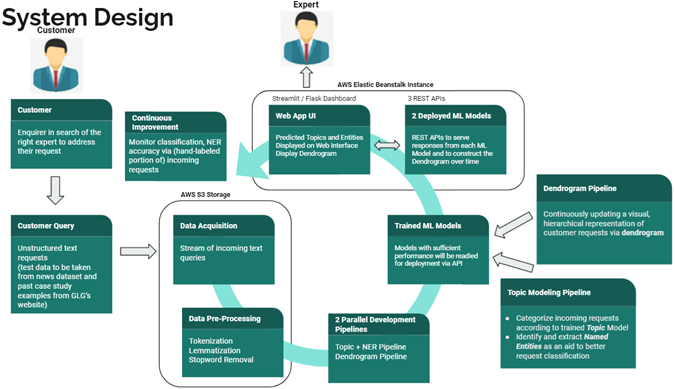
Overall System Architecture:
All code for this project can be found here.


